离散事件模拟 + 强化学习
人工智能
4分钟

系统仿真方法主要有三种类型:离散事件仿真 (DES)、基于代理的建模 (ABM) 和系统动态 (SD)。这里我们主要讨论 DES。
什么是 DES?
离散事件仿真(DES)是一种模拟系统行为和性能的方法。它将系统的操作建模为一系列离散事件在时间上的序列。每个事件在特定的瞬间发生,并标志着系统状态的变化。
它涉及调度和执行改变系统状态的事件。仿真通过逐个处理这些事件来推进,这可能包括随机元素来模拟系统行为的变异性。离散事件仿真的一个额外概念是,在该环境中会有一个时钟来记录当前时间。到了事件触发时刻,事件就会发生。
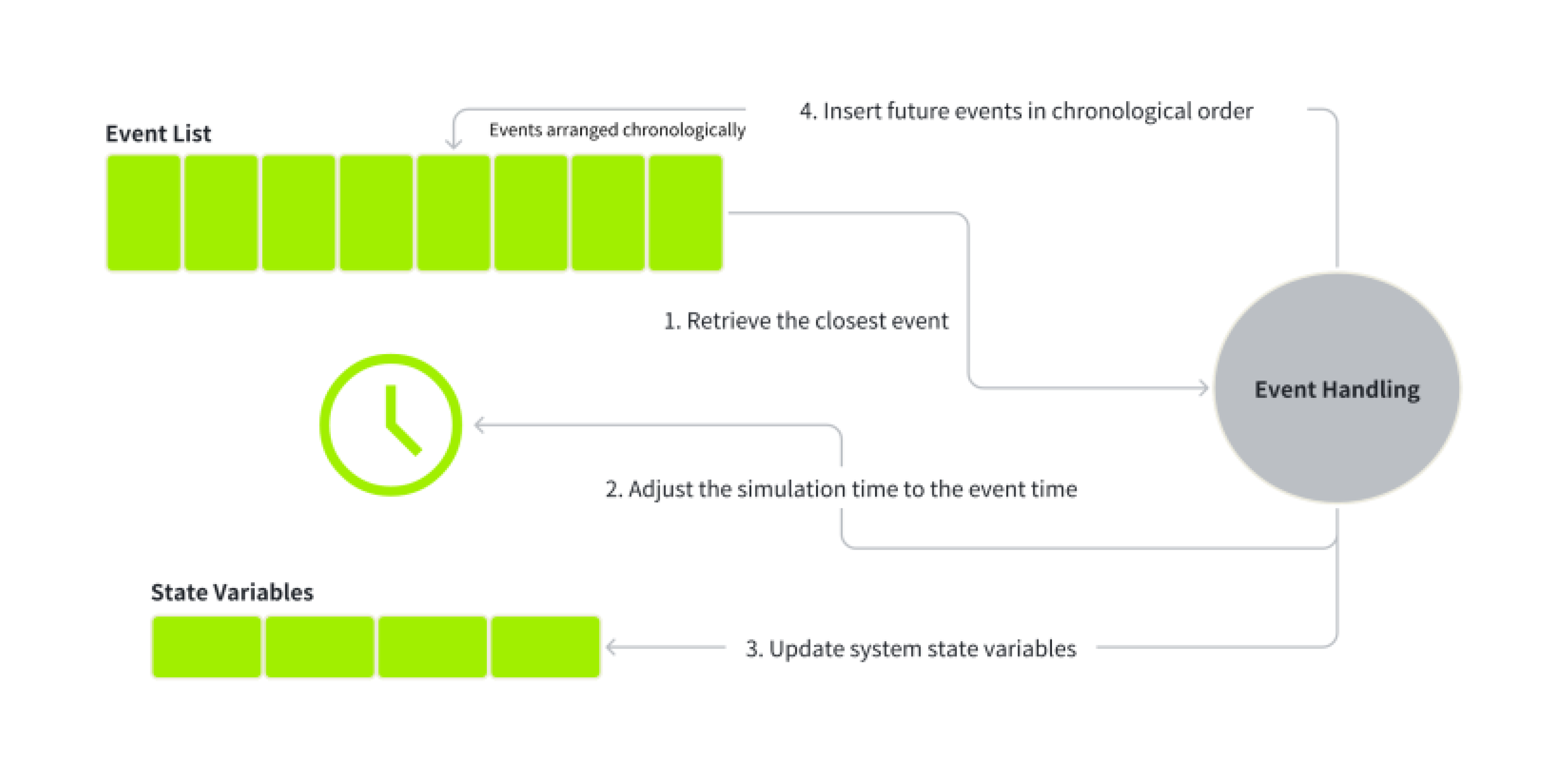
“事件”是指任何改变系统状态的事情发生。术语“离散”指的是我们的重点仅仅在这些事件发生的特定时刻,而忽略其他时间段的无关信息。此类事件的示例包括顾客的到达与离开、资源的分配与释放,以及影响运营的突然、意外事件,如地震等。

鉴于资源有限,离散事件仿真中一个常见场景涉及“等待”资源。例如,这可以在患者在接待区等待医疗咨询时观察到,或者当个体在服务柜台排队买东西时。
DES 与 RL 的结合
在理解离散事件模拟的定义后,这个术语来了 - 强化学习。
强化学习是一种机器学习方法,在这种方法中,代理通过与环境的互动来学习并做出决策。代理开发出一种策略,以优化根据它执行的动作所获得的总奖励。
在强化学习(RL)中,代理通过尝试不同的行动并观察它们如何随时间影响奖励来学习做出最佳决策。与监督学习不同,监督学习提供正确的答案,而 RL 则使用奖励来展示代理的行动效果好坏。代理必须根据这些奖励自行判断。在 RL 中,代理的行动影响即时奖励和未来奖励。由于环境提供的信息有限,代理从自身的经验中学习。它逐渐改善其行动,以更好地适应环境。
训练一个 RL 代理可能会耗费时间,通常需要数十万步才能找到几乎最优的策略。在无模型的马尔可夫决策过程 (MDP) 中,这变得更加复杂,因为代理必须估计与环境互动后不同结果的概率,而不是拥有预定义的概率。
通过为 RL 代理提供一个可控和可重复的环境,模拟成为强化学习 (RL) 中的一种重要工具。这种方法减少了代理在复杂或潜在危险的现实场景中直接互动所带来的风险和成本。离散事件模拟 (DES) 对于建模在特定、独立的时间发生事件的环境特别有价值。这提供了一个结构化却又可适应的框架供 RL 运作,使其非常适合应用。
场景设置
考虑一个医院场景:不同部门有各自的患者队列,服务时间和就诊紧急程度各不相同。这里的目标是最小化整体等待时间,同时确保急诊病例能够优先得到关注。在这种情况下,使用离散事件仿真(DES)进行模拟可以让强化学习(RL)代理实验不同的患者流管理策略、优化服务顺序并有效优先处理患者,在无风险的虚拟环境中进行。
DES医院排队模型
患者到达: 模拟患者的到达,关键属性包括紧急程度、科室和预估服务时间。
队列管理: 每个部门有一个单独的队列。传统的队列管理可能是“先到先服务”或者基于固定的优先级规则。
服务: 模拟服务过程,患者由部门工作人员进行治疗。
RL整合
状态: 定义系统的状态,包括每个队列中的患者数量、当前正在服务的患者以及等待患者的紧急程度。
动作: 在每个决策点(例如,服务一个患者后需要选择下一个患者时),动作可以是从任意队列中选择下一个要服务的患者。
奖励: 设计一个奖励函数,对案例长时等待进行惩罚,尤其是紧急案例,并可能对非紧急案例的短时等待给予奖励。
实施步骤
使用DES模拟环境: 使用DES建模患者流动和服务机制。DES处理患者到达、等待和服务的动态。
应用RL进行决策: 使用RL代理学习从队列中选择患者的最佳策略。代理观察队列的状态,并根据其行为(患者选择)的结果获得奖励。
训练: RL代理从每个交互中(每个患者服务完成和下一个患者选择)持续学习。随着时间的推移,它识别出优化队列管理的最佳模式和策略。
整合: 将RL决策过程整合到DES中,以便在每个决策点上,咨询RL代理选择下一个要服务的患者。
与静态规则不同,RL代理可以适应变化的条件,例如患者的突然增加或科室可用性的变化。RL可以平衡多个目标,例如在最大化急诊病例护理的同时最小化等待时间。随着数据的不断收集,系统可以持续改进,适应新的患者到达模式或医院运营的变化。
实验设计
为了在Python中模拟离散事件系统(DES),如医院排队问题,您可以使用 SimPy 库。SimPy是基于过程的离散事件的标准Python仿真框架。