什么是统一命名空间(UNS)?
UNS
3分钟
统一命名空间(UNS)是一种集中式数据架构,其中所有工业系统——机器、应用程序、传感器和业务工具——通过一个单一、分层组织且带有上下文的数据结构来发布和消费数据,用共享、可复用的数据层取代点对点集成。
从实际角度看,UNS为制造商提供了一个查找工厂信息的公共位置。PLC信号、产线状态、生产工单、异常事件或质量结果,都可以在同一个结构化命名空间中表示。系统不再要求每个应用程序都为其他每个应用程序单独建立连接,而是一次发布数据,并订阅所需内容。
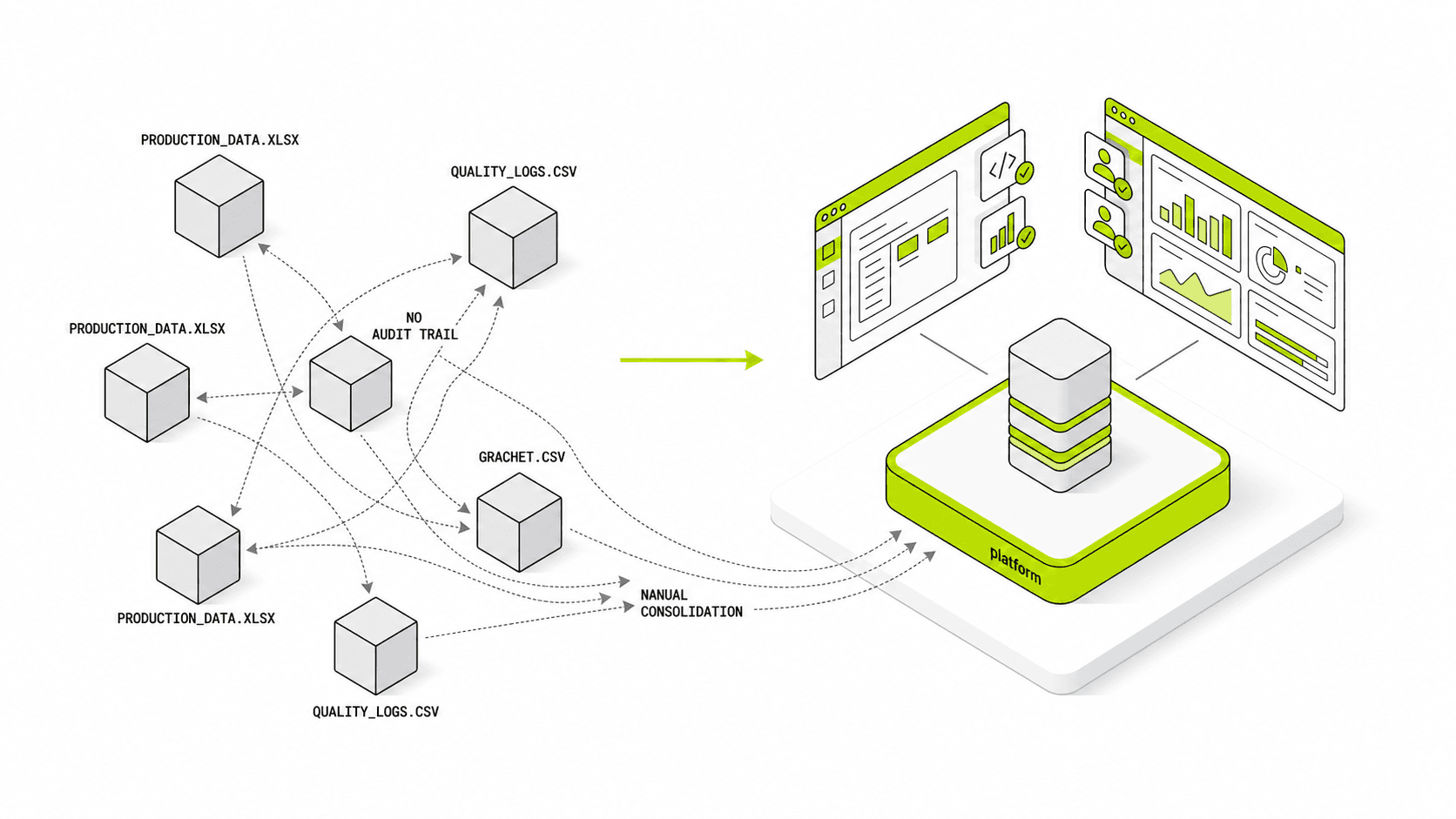
这听起来很技术化,但商业上的原因很简单:工厂通常一次只添加一个软件项目。MES、SCADA、历史数据库、质量工具、仓储工具、报表应用以及定制脚本,都会随着时间逐步接入。结果是点对点集成网络不断增长,维护成本高且难以扩展。UNS旨在以更结构化、可复用的数据基础来取代这种模式。
为什么制造商关心 UNS
大多数制造商起初面对的并不是架构问题,而是运营问题。主管希望在不使用 Excel 的情况下获得生产报告。质量团队希望更快地跟踪异常。工厂希望能看到产线状态的统一视图。IT 团队希望在引入新应用时,不必反复重建集成。
UNS 之所以重要,是因为它能以可扩展的方式帮助解决这些问题。当数据被组织在一个共享结构中时,不同的应用就可以重复使用它。一个轻量级的报表应用可以消费同一份已具上下文的数据,而这些数据也同样支持仪表板、告警流程,或日后的分析用例。这就是长期价值所在:不仅是今天更快地集成,更是明天更低的集成摩擦。
统一命名空间如何工作
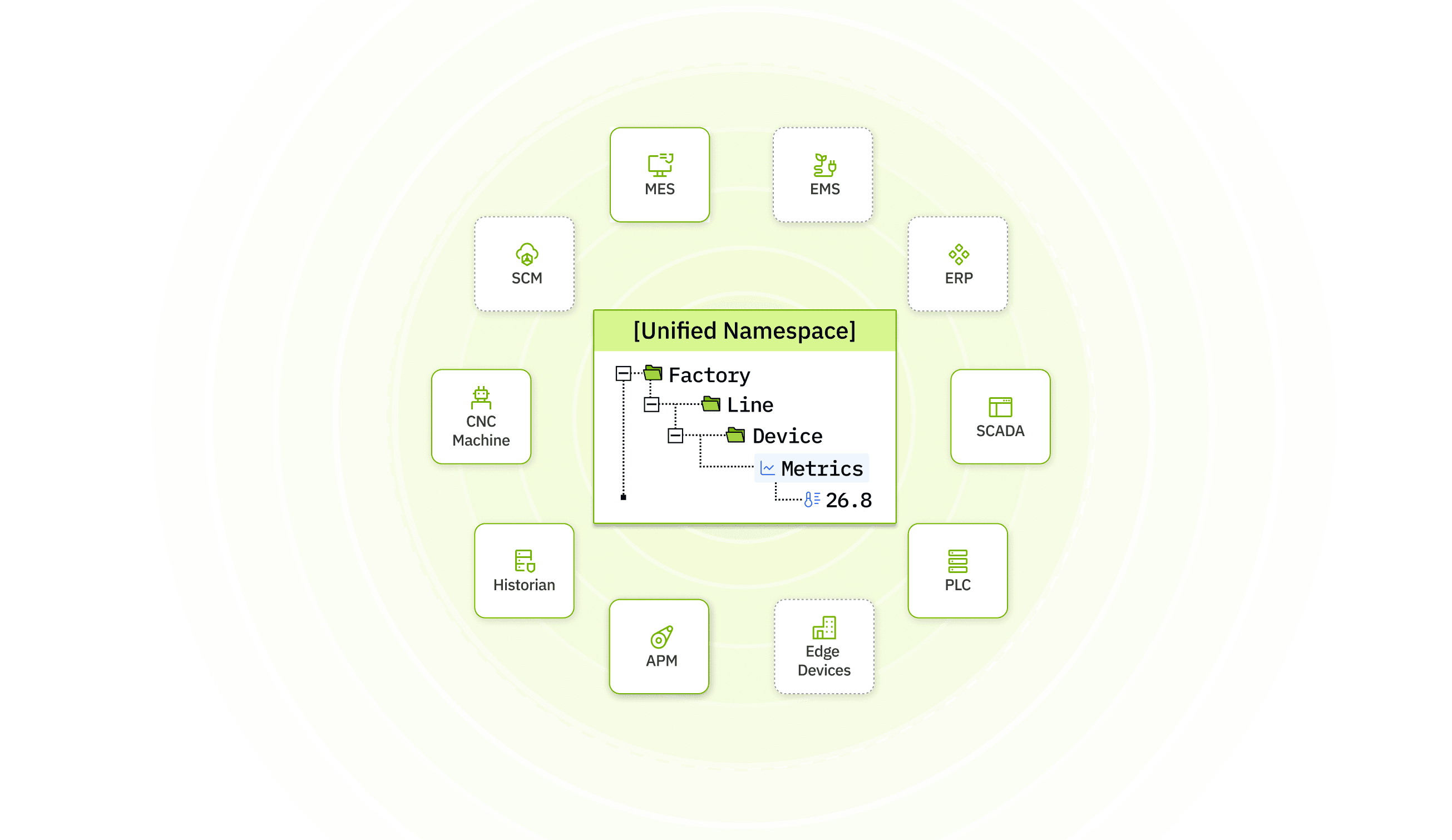
UNS 通常基于发布-订阅模型,而不是直接的一对一系统调用。数据生产者将更新发布到公共命名空间中。数据消费者订阅他们需要的主题。命名空间本身提供上下文、命名和结构。
一个简单的示例如下:
企业 / 站点 / 区域 / 产线 / 机器
该结构下的状态、指标、告警、物料、工单或质量数据
应用程序订阅相关主题,而不是向每个来源分别请求自定义 API
当相同数据需要被多个消费者复用时,这种方法尤其有用。与其为同一机器状态构建五个单独的集成,不如将状态只发布一次并重复使用。
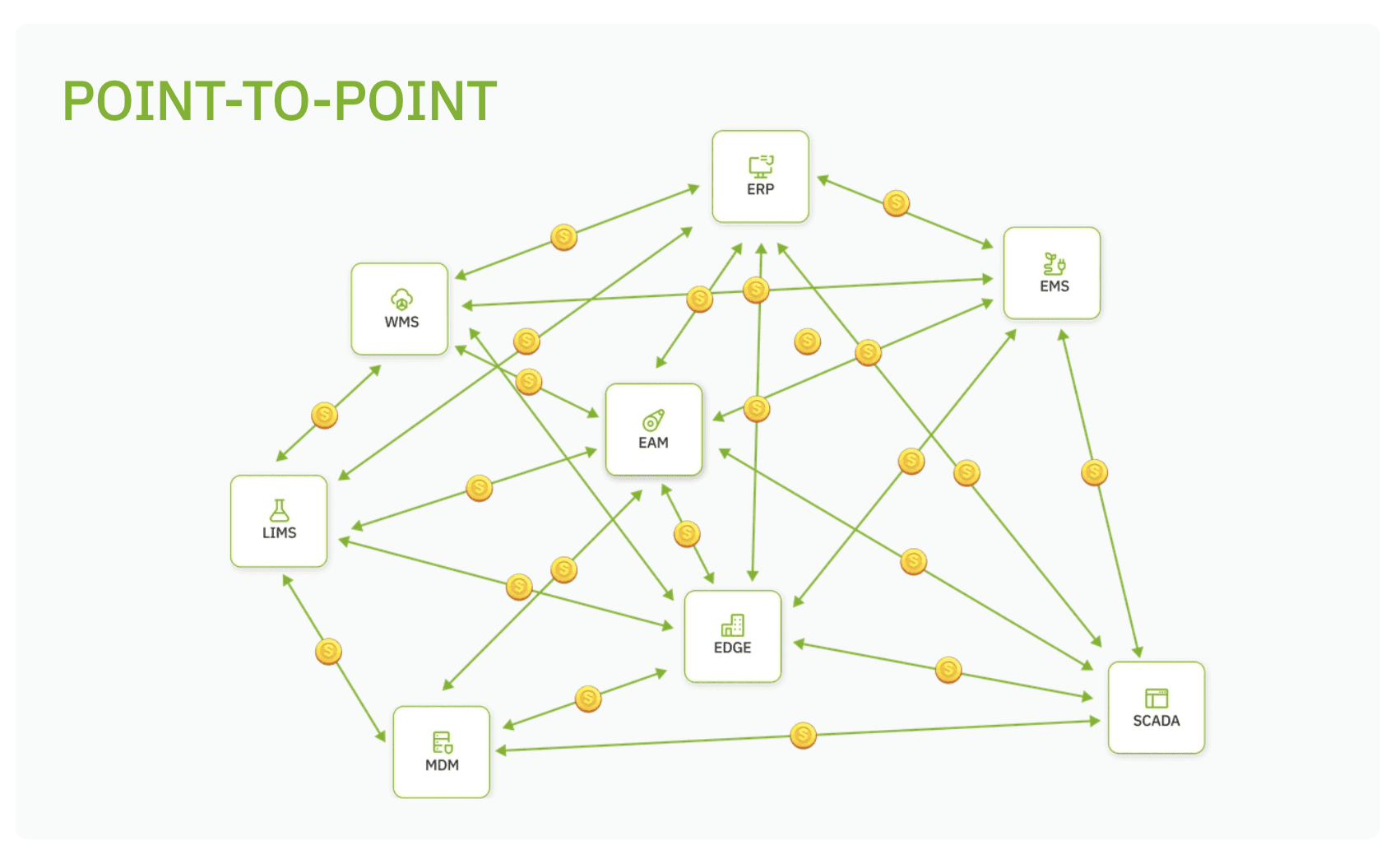
UNS 与传统集成
传统集成通常由项目驱动。一个系统需要来自另一个系统的数据,因此会构建一个直接接口。然后另一个项目需要类似的数据,于是又添加一个接口。随着时间推移,架构会变得难以理解且变更成本高昂。
UNS 改变了这种模式。数据只需一次建模到共享命名空间中,然后可被多个下游应用复用。这并不会消除所有集成工作,但会显著减少重复的集成工作量。
其差异在于战略层面。点对点集成回答的问题是,“我如何连接这两个系统?”UNS 回答的问题是,“我如何创建一种可复用的工业数据结构,使许多系统能够协同工作,而不会每次都制造新的信息孤岛?”

UNS 不是什么
UNS 不是一种可以替代工厂中每一个系统的神奇产品类别。它不会自动成为历史数据库,不会自动成为 MES,也不会自动成为数据湖。如果命名、结构和治理薄弱,它也不会有价值。
一个好的 UNS 需要清晰的建模规则、上下文数据、所有权以及运行纪律。否则,它就可能只是另一条消息管道。