What is Unified Namespace (UNS)?
UNS
3 minutes
A Unified Namespace (UNS) is a centralized data architecture in which all industrial systems—machines, applications, sensors, and business tools—publish and consume data through a single, hierarchically organized and contexted structure, replacing point-to-point integrations with a shared, reusable data layer.
In practical terms, a UNS gives a manufacturer a common place to find plant information. A PLC signal, a line status, a production order, an abnormal event, or a quality result can all be represented in the same structured namespace. Instead of asking each application to build a separate connection to every other application, systems publish data once and subscribe to what they need.
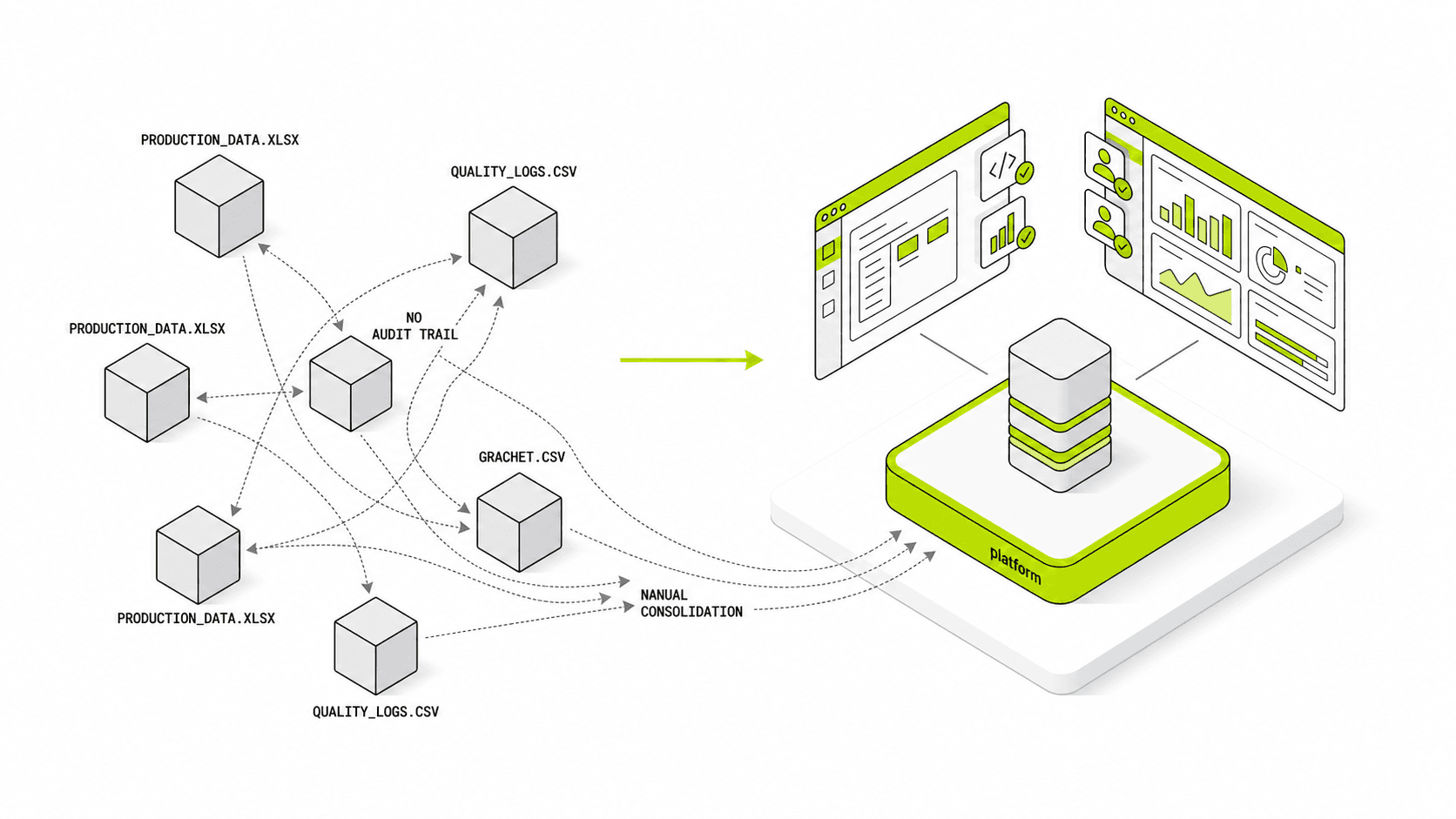
That sounds technical, but the business reason is simple: factories usually add software one project at a time. MES, SCADA, historians, quality tools, warehouse tools, reporting apps, and custom scripts all get connected over time. The result is a growing web of point-to-point integrations that is expensive to maintain and hard to expand. A UNS is meant to replace that pattern with a more structured, reusable data foundation.
Why manufacturers care about UNS
Most manufacturers do not start with an architecture problem. They start with an operational problem. A supervisor wants production reporting without Excel. A quality team wants faster abnormal tracking. A plant wants one view of line status. An IT team wants to stop rebuilding integrations whenever a new application is introduced.
A UNS matters because it helps solve those problems in a way that scales. When data is organized in one shared structure, different applications can reuse it. A lightweight reporting app can consume the same contextualized data that also supports a dashboard, an alerting flow, or a later analytics use case. That is where the long-term value comes from: not only faster integration today, but lower integration friction tomorrow.
How a Unified Namespace works
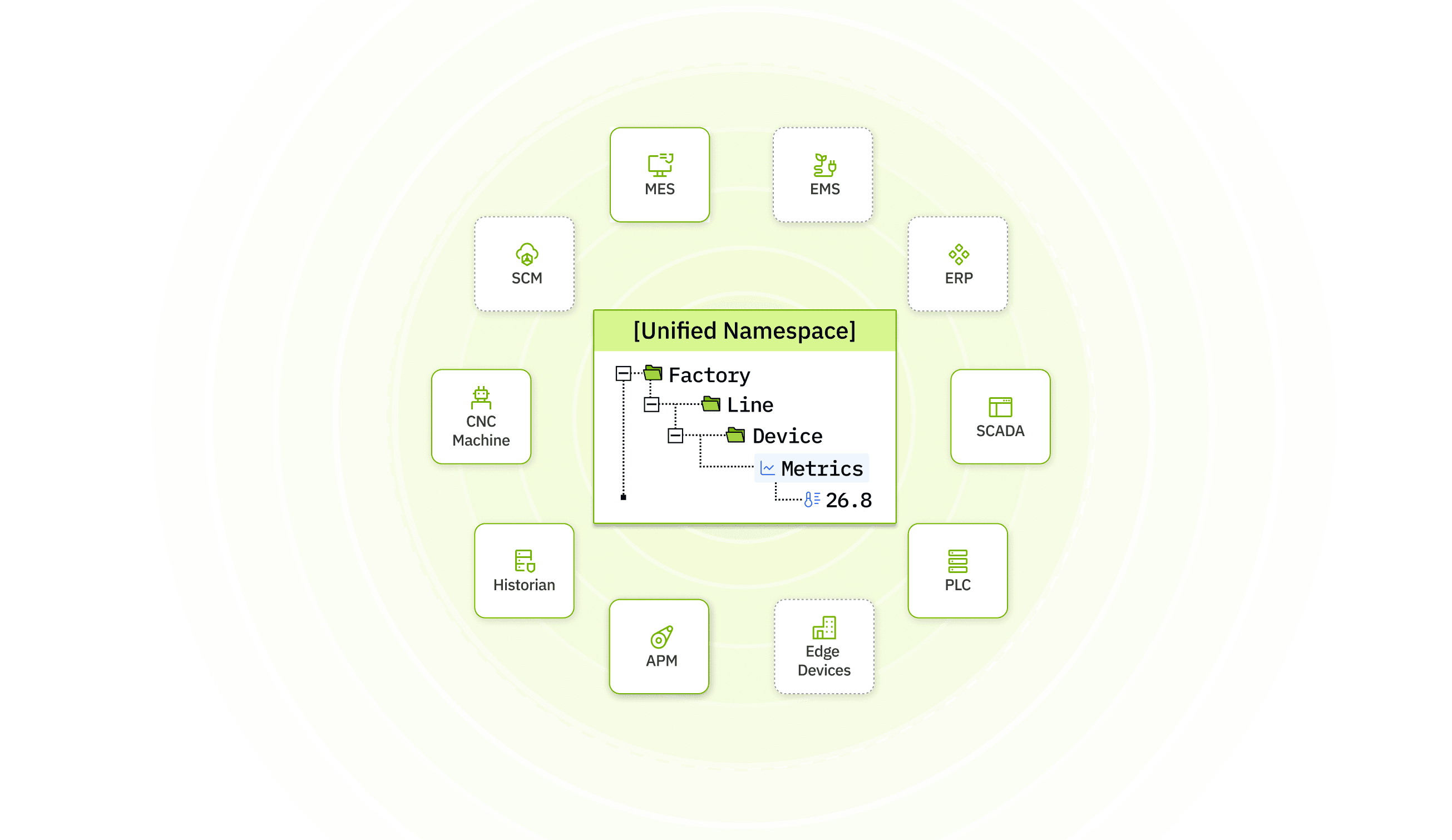
A UNS is usually built on a publish-and-subscribe model rather than direct one-to-one system calls. Data producers publish updates into a common namespace. Data consumers subscribe to the topics they need. The namespace itself provides context, naming, and structure.
A simple example might look like this:
Enterprise / Site / Area / Line / Machine
Status, metrics, alarms, material, work order, or quality data under that structure
Applications subscribe to relevant topics instead of asking each source for separate custom APIs
This approach is especially useful when the same data needs to be reused by several consumers. Instead of building five separate integrations for the same machine state, the state is published once and reused.
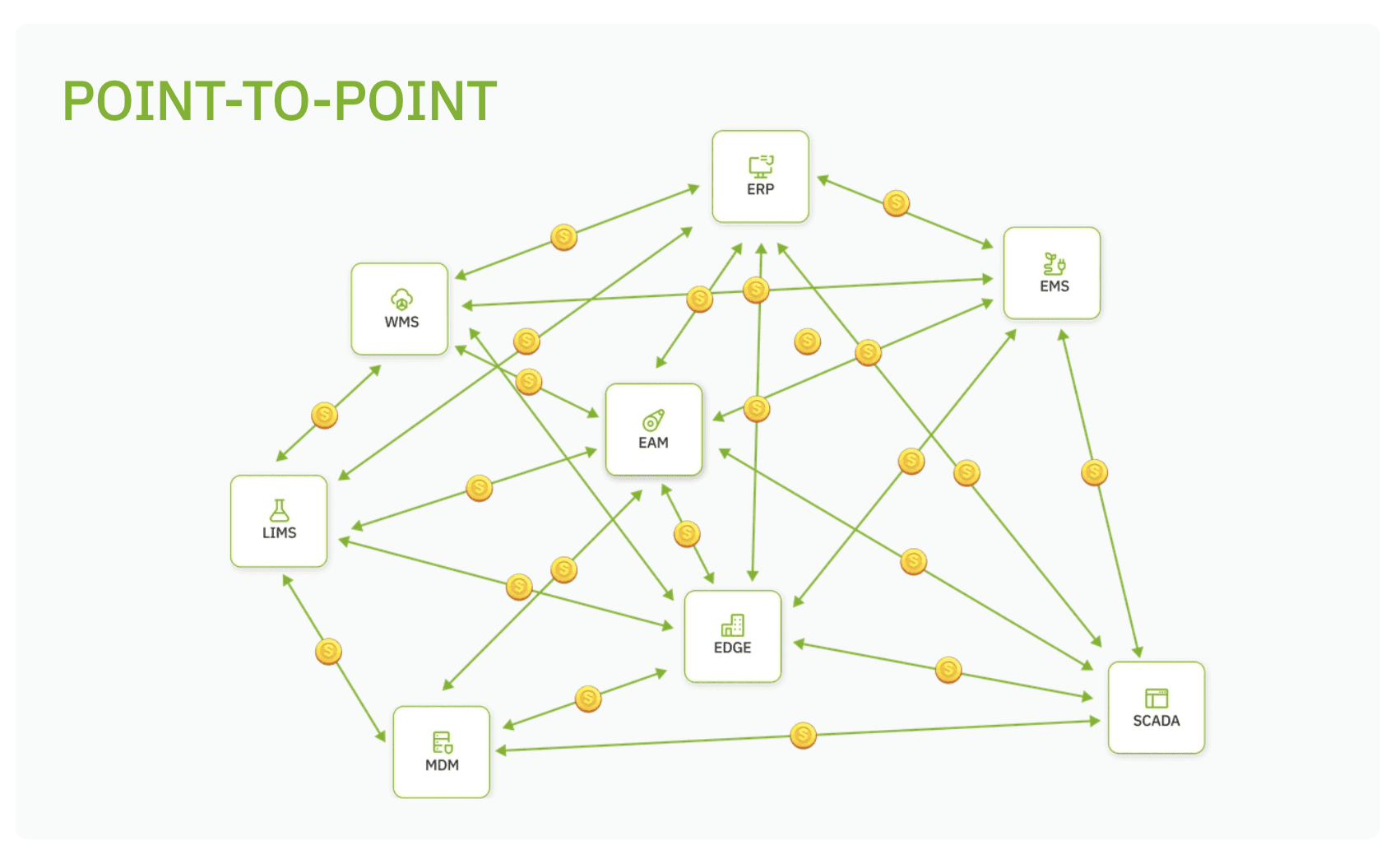
UNS vs Traditional integration
Traditional integration is often project-driven. One system needs data from another system, so a direct interface is built. Then another project needs similar data, so another interface is added. Over time, the architecture becomes hard to understand and expensive to change.
A UNS changes the pattern. Data is modeled once into a shared namespace and then reused by multiple downstream applications. That does not eliminate all integration work, but it significantly reduces repeated integration effort.
The difference is strategic. Point-to-point integration answers the question, “How do I connect these two systems?” A UNS answers the question, “How do I create a reusable industrial data structure so that many systems can collaborate without creating new silos every time?”

What a UNS is not
A UNS is not a magic product category that replaces every system in a factory. It is not automatically a historian, not automatically an MES, and not automatically a datalake. It is also not valuable if naming, structure, and governance are weak.
A good UNS needs clear modeling rules, contextual data, ownership, and operating discipline. Without that, it can become just another message pipe.