Tier0 对比 HighByte:是工业 DataOps 组件,还是带有 AI 生成应用的全栈 UNS 平台?
产品
3分钟

HighByte 被广泛应用于工业 DataOps 和统一命名空间(UNS)的实施。其 Intelligence Hub 可帮助制造商对工业数据进行标准化和上下文关联,以便下游系统能够消费建模后的信息,而不是原始标签。对于那些核心缺失层是数据上下文关联的团队来说,HighByte 是一个可靠且专注的选择。
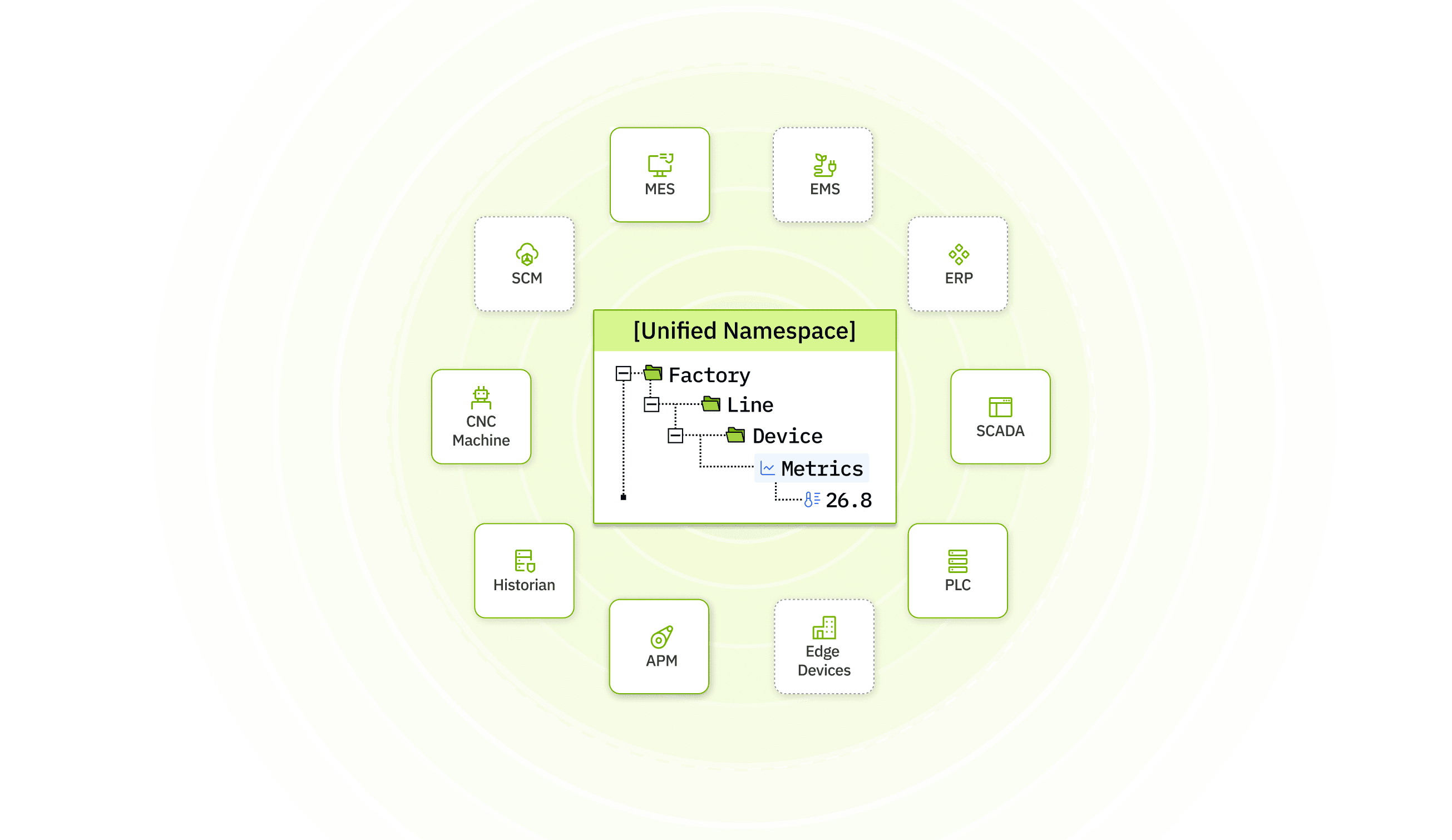
Tier0 在架构中扮演着不同的角色。HighByte 通常用作组装好的 UNS 堆栈中间的工业 DataOps 组件。而 Tier0 是一个全栈 UNS 平台:命名空间、SourceFlow、EventFlow、时序持久化、Notebook 和 App Builder 被产品化为一个统一平台。这两款产品并不处于 UNS 堆栈的同一层级。
范围对比
能力 | HighByte Intelligence Hub | Tier0 |
|---|---|---|
数据采集 | 连接工业数据源进行建模工作流。 | 将 SourceFlow 作为产品化的采集模块。 |
事件处理与 MQTT 分发 | 与外部消息传输和下游目的地集成。 | EventFlow,包括基于 MQTT 的分发。 |
历史数据库 / 时序数据 | 通常与外部历史数据库集成。 | 内置 TimescaleDB,同时也支持第三方历史数据库。 |
语义建模、ISA-95、UNS 上下文关联 | 核心优势。专注于工业 DataOps。 | 将 Namespace(命名空间)作为平台的原生语义模型。 |
分析 / 笔记本 (Notebook) | 通常由下游系统处理。 | 连接到相同 UNS 基础的 Notebook。 |
应用生成 | 通常由下游系统或定制应用处理。 | App Builder 通过自然语言生成 UNS 原生应用。 |
开箱即用的功能 | 工业 DataOps 中间件。 | 完整的 UNS 基础加上 AI 应用生成。 |
两种不同形态的价值
HighByte 的价值在于单层深度。如果上下文语境化是瓶颈——如果原始标签是下游系统无法消费运营数据的真正原因——HighByte 能够很好地解决这一特定问题,并能与团队现有的任何代理(broker)、历史数据库和应用技术栈集成。
Tier0 的价值则在于广度加生成。Tier0 涵盖了 HighByte 未涉及的层级(采集、事件处理与 MQTT 分发、持久化、分析、应用),并且它还提供了一项 HighByte 和市场上大多数产品都不具备的功能:工艺工程师、质量工程师或维护工程师能够用自然语言描述一个应用程序,并获得一个可以运行的 App——该 App 可以与所有其他 Tier0 App 读写同一个命名空间(Namespace)。
差距真正显现的地方:应用层
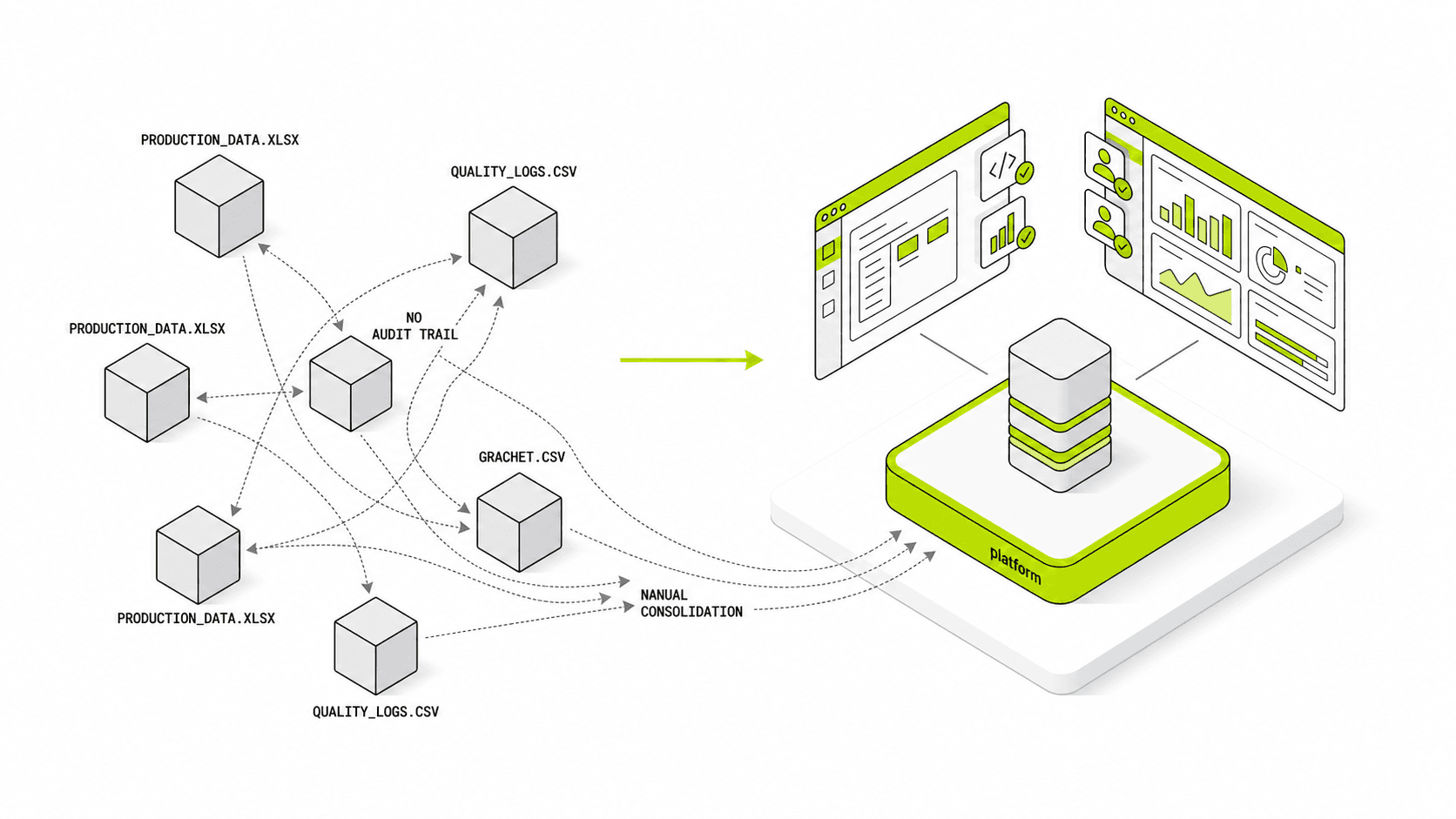
即使在 HighByte 对数据进行了上下文处理之后,仍然需要有人来构建消费这些数据的应用程序。在 HighByte 的世界中,这些应用程序通常是下游系统——由集成商或内部开发人员设计,每个系统都有自己的数据模型、自己的 UI 框架以及自己与命名空间的反向集成。上下文处理后的数据是一致的;但消费这些数据的应用程序却不是。
在 Tier0 的世界中,应用程序被设计为平台的一部分。它们是由 App Builder 直接从命名空间生成的,并且默认是 UNS 原生的:它们共享相同的语义模型、相同的身份验证和相同的写回路径。相隔六个月生成的停机报告和维护工单应用程序不需要单独的集成工作来共享“设备”的定义。
HighByte 实现了数据标准化。Tier0 则实现了数据以及消费这些数据的应用程序的标准化。
何时 HighByte 可能是更好的选择
如果您的团队已经拥有成熟的应用栈,且仅需要一个专注的工业 DataOps 层来为其提供数据流,那么 HighByte 可能是更合适的选择。在这种情况下,团队通常具备工程开发能力、已定义的应用标准,并且更偏好基于组件的架构。
何时 Tier0 可能是更好的选择
如果团队希望将 统一命名空间(UNS)基础 、时间序列持久化、分析以及正常运行的工业应用程序整合交付,并且希望工程人员(而非专业开发人员)使用自然语言来生成这些应用程序,那么 Tier0 可能是更合适的选择。如果目标是在共享的语义基础之上,快速交付 制造执行系统(MES)风格、仓库管理系统(WMS)风格、质量、停机时间和维护应用程序,那么 Tier0 的全栈式和 AI 原生方法将是更直接的途径。